[AINews] Mistral Small 3 24B and Tulu 3 405B • ButtondownTwitterTwitter
Chapters
Mistral Small 3 and Tulu 3 405B Model Releases
DeepSeek R1 Speeds and Snags
Community Discussions on Various AI Models and Tools
Hardware and Software Discussions in AI Discord Communities
Discord Highlights
OpenAI GPT-4 Discussions
Introducing New Features and Discussions in LM Studio
Nous Research AI Discussion
Interconnects: Nathan Lambert Collections
Stability.ai Hardware and Tool Discussions
Using tl.gather and Triton Limitations
User Feedback and Testing Opportunities
Insights on Various AI Discussions
Mistral Small 3 and Tulu 3 405B Model Releases
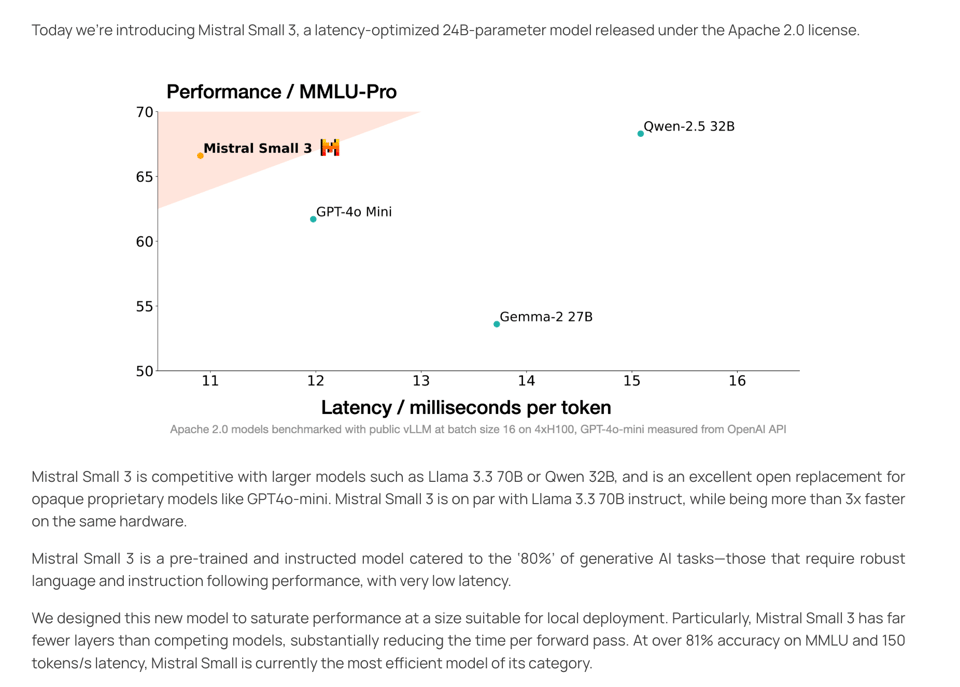
The section discusses the release of Mistral Small 3 and Tulu 3 405B models. Mistral Small 3, a VC backed project, was released with optimized features for local inference. On the other hand, AI2 released the Tulu 3 405B model, showcasing its scalability and competitive performance. The section also highlights the absence of hosted APIs at the launch of Tulu 3 405B model, limiting immediate accessibility. Additionally, the section provides a glimpse into upcoming sections covering AI Twitter and Reddit recaps, along with detailed summaries of various AI-related discord channels.
DeepSeek R1 Speeds and Snags
The DeepSeek R1 model, particularly the 1.58B version, operates at a rate of approximately 3 tokens per second on basic hardware, necessitating 160GB VRAM or fast storage for optimal performance. Users have reported varying speeds, with some achieving 32 TPS on high-end GPUs. Challenges with quantized versions impacting instruction following have also been highlighted. Recommendations include using Linux over Windows for improved quantization performance.
Community Discussions on Various AI Models and Tools
The community engaged in lively discussions covering a range of AI models and tools across different Discord channels. From praising DeepSeek's stable privacy features to comparing GPT-4, Sonnet, and Gemini 2.0 for advanced queries, users debated the performance, cost-efficiency, and overall capabilities of these tools. Additionally, topics such as the performance surges of DeepSeek on various GPU setups, the introduction of new tools like OneClickPrompts, and the potential of fine-tuning AI models for domain-specific tasks generated interest and discussion. The community also delved into debates surrounding AI ethics, model security, and the implications of large-scale investments in AI development. Overall, these discussions reflected a diverse range of viewpoints and concerns within the AI community.
Hardware and Software Discussions in AI Discord Communities
In this section, various AI Discord communities engage in discussions related to hardware and software aspects of AI. Discussions range from GPU comparisons and hardware options like Intel Arc A770 LE and Nvidia RTX models, to software updates like PyTorch 2.6's new features. Members of different communities also share insights on face swap functionalities, training techniques for Stable Diffusion, and challenges in model documentation. The section covers diverse topics such as stable diffusion, deep learning models, GPU optimizations, and AI tool development.
Discord Highlights
OpenInterpreter Discord
- Farm Friend Mystery: Community members are curious about the absence of 'Farm Friend' from last year's discussions, with its fate remaining unknown.
- Cliché Reviews Spark Amusement: Playful banter ensued over cliché reviews, adding a fun moment within the community.
- Decoding '01': A user clarified that '01' was unrelated to OpenAI, dispelling prior confusion.
Torchtune Discord
- Boost Checkpoints with DCP Toggle: Members discussed activating DCP checkpointing for full_finetune_distributed, noting limited functionality for other configurations.
- Push for Wider Checkpoint Coverage: The community expressed interest in expanding async checkpointing support across all configurations for easier large-scale finetuning.
LAION Discord
- Local Img2Vid Craze: Users discussed the best local img2vid tool and emphasized clear documentation for AI workflows.
- ltxv Gains Favor: A member promoted 'ltxv' for img2vid tasks, hoping for community-driven benchmarks and expanded model support.
MLOps @Chipro Discord
- Simba Sparks a Databricks Feature Frenzy: An MLOps Workshop by Simba Khadder on building feature pipelines with Unity Catalog integration on Databricks was announced.
- Databricks Embraces Geospatial Analytics: A session on advanced geospatial analytics processing on Databricks was scheduled, offering insights into spatial data processing.
OpenAI GPT-4 Discussions
Next Generation AI Instructions, Memory Function in GPT Models, API and Custom GPT Limitations, OpenAI's Model Release Intentions, Fine-tuning Ollama Models
- A user suggests AI should follow instructions rather than perform text manipulation, ensuring consistent responses through Custom GPT.
- Memory features in GPT models are discussed, highlighting challenges in maintaining context awareness during lengthy discussions.
- Users report issues with API and custom GPT, including inconsistencies in scraping links for projects.
- Opinions vary on whether OpenAI releases models in bad faith to hinder competitor models.
- User interest in fine-tuning Ollama models reflects a broader trend of customizing AI for specific applications.
Introducing New Features and Discussions in LM Studio
LM Studio introduces new features like Idle TTL for smart memory management, Separate Reasoning Content, and New Auto-Update Feature for Runtimes. Users can set a time-to-live for API models with Idle TTL, access reasoning details separately with reasoning_content field, and streamline updating processes with auto-update. Discussions in the community cover topics such as DeepSeek model compatibility, RAG capabilities, model performance and reasoning, customization and UI tweaks, and general praise for LM Studio's progress. Users report issues with DeepSeek models, inquire about RAG support, discuss model reasoning capabilities, express interest in UI flexibility, and share excitement about utilizing powerful models. Additionally, the section provides links to documentation and resources for further optimization and understanding of LM Studio's features.
Nous Research AI Discussion
The Nous Research AI channel discusses various topics related to AI technology and developments. In the recent conversations: 1. Nous x Solana event in NYC generated buzz, with attendees excited about infrastructure discussions for distributed training in AI models. 2. Community members eagerly await new model releases, like Mistral Small, hoping for performance comparisons. 3. Psyche, a distributed training network for open AI models, received positive feedback for its innovative approach in facilitating large-scale Reinforcement Learning. 4. There is ongoing engagement around open-sourcing Psyche for consensus algorithms and better accessibility through GitHub. 5. Members are exploring AI agents associated with Nous and its implications for AI development within the ecosystem.
Interconnects: Nathan Lambert Collections
The Interconnects section discusses a variety of topics related to recent AI developments. It includes discussions on the launch of Tülu 3 405B and Mistral Small 3 models, sensitive data leakage from DeepSeek, OpenAI's new technology presentation in Washington, and SoftBank's interest in investing in OpenAI. Additionally, the section explores concerns over Meta's licensing, Deepseek's methodologies, and speculations on model performance. The section also delves into emerging reasoning models, FP8 support rumors, and the challenges of balancing licenses in the AI landscape.
Stability.ai Hardware and Tool Discussions
The discussion in Stability.ai channel revolves around various topics including ComfyUI's manual control for inpainting and flexibility, hardware specifications for running Stable Diffusion effectively, removal and re-upload of the Reactor tool with safeguards for face swapping, training Loras for Stable Diffusion, and the availability and sell-out of new GPUs like the 5090. Users share experiences, seek advice, and express opinions on optimizing tools and hardware choices for AI workloads.
Using tl.gather and Triton Limitations
Triton Tensor Indexing, Using tl.gather, InterpreterError`
-
Triton Unable to Index Tensor Columns: A user faced an InterpreterError when trying to extract a single column from a tensor using
x[:, 0], indicating a limitation in Triton's tensor indexing capabilities. -
Efficiency Concerns with tl.gather: The user considered using
tl.gatherwith an index tensor set to all zeros to extract the column but raised worries about efficiency compared to direct indexing.
User Feedback and Testing Opportunities
Feedback is actively sought from community members on the evolving Hataraku project, with an emphasis on direct messaging for insights. Neil expresses interest in testing the new interface to provide valuable feedback based on their user experience with complex workflows. In addition, NotebookLM is organizing remote chat sessions to gather user feedback on their product, offering participants $75 for insights. The upcoming usability study on February 6th, 2025, requires a high-speed Internet connection, active Gmail account, and a device with video and audio capabilities to gather feedback for future product enhancements.
Insights on Various AI Discussions
Within the AI community discussions, members explored topics such as distillation frameworks, Command R capabilities, Axolotl AI, OpenInterpreter, Torchtune, LAION, MLOps, and Gorilla LLM. These discussions covered queries about adding proxies to adapters, supported LLMs in DSPy, Mistral model releases, checkpointing integration, img2vid tools, MLOps workshops, and making BFCL data HF datasets compliant. The conversations also touched on user preferences, model performance uncertainty, upcoming events, and community humor through meme analysis and cliche reviews.
FAQ
Q: What models were discussed in the section?
A: The Mistral Small 3 and Tulu 3 405B models were highlighted in the section.
Q: What are the key features of Mistral Small 3?
A: Mistral Small 3, a VC backed project, was released with optimized features for local inference.
Q: What was notable about the release of the Tulu 3 405B model?
A: The release of the Tulu 3 405B model showcased its scalability and competitive performance, but there was an absence of hosted APIs at the launch, limiting immediate accessibility.
Q: What are the hardware requirements for the DeepSeek R1 model?
A: The DeepSeek R1 model, especially the 1.58B version, operates at a rate of approximately 3 tokens per second on basic hardware, necessitating 160GB VRAM or fast storage for optimal performance.
Q: What challenges were highlighted regarding quantized versions of AI models?
A: Challenges with quantized versions impacting instruction following have been emphasized, suggesting the use of Linux over Windows for improved quantization performance.
Q: What were the topics of discussion in various AI Discord communities?
A: Discussions ranged from GPU comparisons, hardware options like Intel Arc A770 LE and Nvidia RTX models, to software updates like PyTorch 2.6's new features, face swap functionalities, training techniques, model documentation challenges, stable diffusion, deep learning models, GPU optimizations, and AI tool development.
Q: What were some of the topics discussed in the Nous Research AI channel?
A: Topics included discussions on infrastructure for distributed training in AI models, anticipation for new model releases like Mistral Small, positive feedback on Psyche for large-scale Reinforcement Learning, the open-sourcing of Psyche, and exploring AI agents associated with Nous.
Q: What were the main subjects covered in the Interconnects section?
A: The Interconnects section discussed the launch of Tulu 3 405B and Mistral Small 3 models, sensitive data leakage, OpenAI's new technology presentation, SoftBank's investment in OpenAI, Meta's licensing concerns, Deepseek's methodologies, model performance speculations, reasoning models, FP8 support rumors, and license balancing in the AI landscape.
Q: What were the discussions in the Stability.ai channel focused on?
A: Discussions included topics such as ComfyUI's manual control for inpainting, hardware specifications for running Stable Diffusion effectively, Reactor tool safeguards for face swapping, training Loras for Stable Diffusion, and the availability of new GPUs like the 5090.
Q: What issues were faced related to Triton and tl.gather in the Triton Tensor Indexing discussion?
A: A user faced an **InterpreterError** when trying to index tensor columns in Triton, and efficiency concerns were raised regarding using tl.gather compared to direct indexing.
Q: What feedback is being sought in the evolution of the Hataraku project?
A: Feedback is sought from community members on Hataraku, with an emphasis on direct messaging for insights.

Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!